
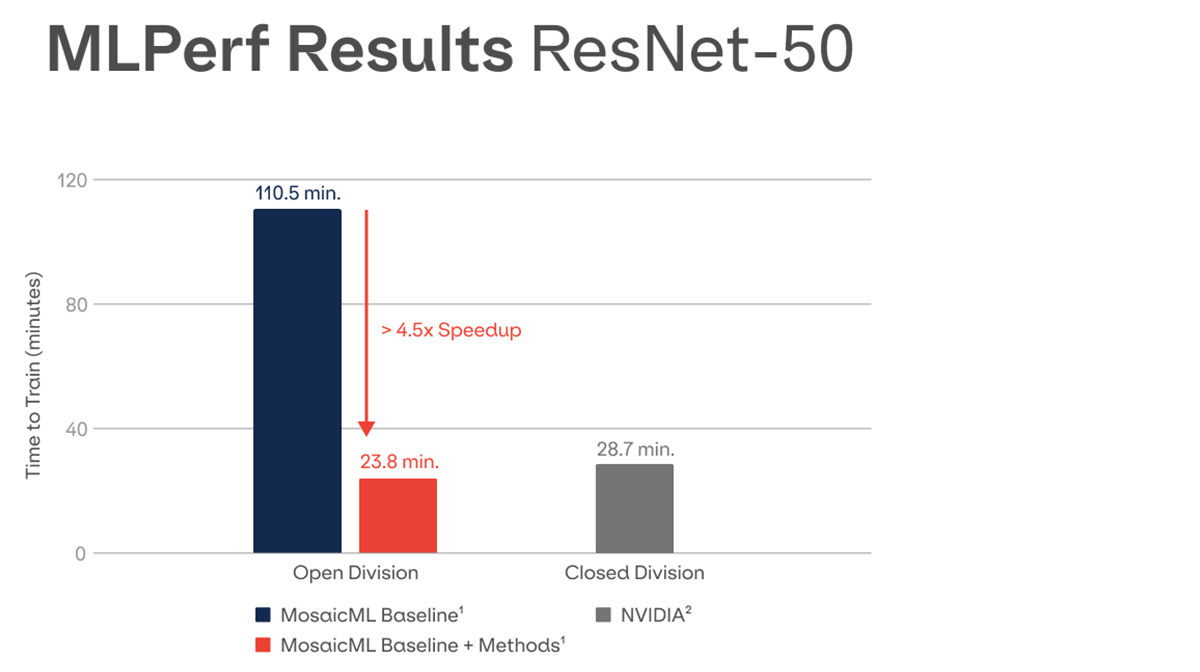
MosaicML’s Open Division submission to the MLPerf Image Classification benchmark delivers a score of 23.8 minutes (4.5x speed-up relative to our baseline) on 8x NVIDIA A100 GPUs. Our results show how algorithmic speedups written in PyTorch deliver ML innovation that truly can benefit everyone, from academic researchers to enterprise practitioners.
MLPerf is an AI performance benchmark that is home to some of the fastest code on the planet, fine-tuned by each hardware vendor. However, for enterprise machine learning practitioners, MLPerf results have largely been inaccessible. Jaw-dropping results (ResNet-50 on ImageNet in just a few minutes!) often employ rarely used frameworks (like MXNet) and bespoke implementations that look completely different from the solutions produced by working data scientists. Each benchmark relies on hardware-targeted custom code loaded with tricks to squeeze out every last ounce of performance, tailored to the exact models or datasets under test. While impressive, it's difficult for enterprise data scientists to enjoy these extraordinary speedups in their everyday work, because the techniques employed rarely generalize to any other use case.
MosaicML’s mission is to make AI model training more efficient for everyone. In service of that goal, our submission to MLPerf Training 2.0 brings MLPerf-level speed to data scientists and researchers. We use general purpose training code built on PyTorch, and include algorithmic efficiency methods, all wrapped into our open-source library Composer. These optimizations can be applied to your own model architectures and datasets with just a few lines of code.
Results
Our open result of 23.8 minutes is 17% faster than NVIDIA’s submission of 28.7 minutes in the closed division on the same hardware.
We submitted two results to the MLPerf Training Open division’s Image Classification benchmark. The first result is our baseline ResNet-50, which uses standard hyperparameters from research. The second result adds our algorithmic efficiency methods with just a few lines of code, and achieves a 4.5x speed-up (23.8 minutes) compared to our baseline (110.5 minutes), on 8x NVIDIA A100-80GB.1
Our open result of 23.8 minutes is 17% faster than NVIDIA’s submission of 28.7 minutes in the closed division on the same hardware.2 Our submission uses PyTorch instead of MXNet, includes more common research hyperparameters, and adds algorithmic techniques for more efficient training.3
| Submission | MLPerf Division | Time to Train4 (minutes) | Framework | Hyperparameters |
|---|---|---|---|---|
| MosaicML ResNet-50 Baseline1 | Open | 110.5 | PyTorch | MosaicML Research Baseline Hyperparameters (Derived from NVIDIA Deep Learning Examples) |
| MosaicML ResNet-50 Optimized1 with Composer Speedup Methods | Open | 23.8 | PyTorch | MosaicML Research Baseline Hyperparameters (Derived from NVIDIA Deep Learning Examples) |
| NVIDIA ResNet-50 Optimized2 | Closed | 28.7 | MXNet | Optimized for MLPerf |
Our techniques preserve the model architecture of ResNet-50, but change the way it is trained. For example, we apply Progressive Image Resizing, which slowly increases the image size throughout training. These results demonstrate why improvements in training procedure can matter as much, if not more, than specialized silicon or custom kernels and compiler optimizations. Deliverable purely through software, we argue that these efficient algorithmic techniques are more valuable and also accessible to enterprises.
For more details on our recipes, see our Mosaic ResNet blog post, and our submission code README.
Put our MLPerf Submission to Work for You!
Since adding algorithms requires just a few lines of code, test our recipes on your own datasets, or experiment with algorithm combinations, by using the code below with your own models and datasets.
from composer import Trainer, algorithms
trainer = Trainer(
model=your_classification_model,
train_dataloader=your_dataloader,
optimizers=your_optimizer,
schedulers=your_scheduler,
# speed-up algorithms below
algorithms=[
algorithms.BlurPool(),
algorithms.ChannelsLast(),
algorithms.LabelSmoothing(
alpha=0.1
),
algorithms.ProgressiveResizing(
size_increment=4,
delay_fraction=0.4
),
algorithms.EMA(
update_interval='20ba',
)
],
)
trainer.fit()Looking for faster training on other workloads? Stay tuned as we release fast recipes for NLP models, semantic segmentation, object detection, and more! Questions? Contact us at [email protected]!
1 Official MLPerf 2.0 Training results. Baseline: 2.0-2126; Methods: 2.0-2127
2 Official MLPerf 2.0 Training results. NVIDIA: 2.0-2090
3 Our baseline of 110.5 minutes is slower than NVIDIA’s submission of 28.7 minutes because we use PyTorch instead of MXnet, and more common research hyperparameters instead of benchmark-optimized hyperparameters. As our methods demonstrate, our algorithmic efficiencies more than compensate, leading to a 17% improvement. Future work can combine these approaches.
4 The MLPerf Image Classification score measures time to train to 75.9% validation accuracy on ImageNet.