
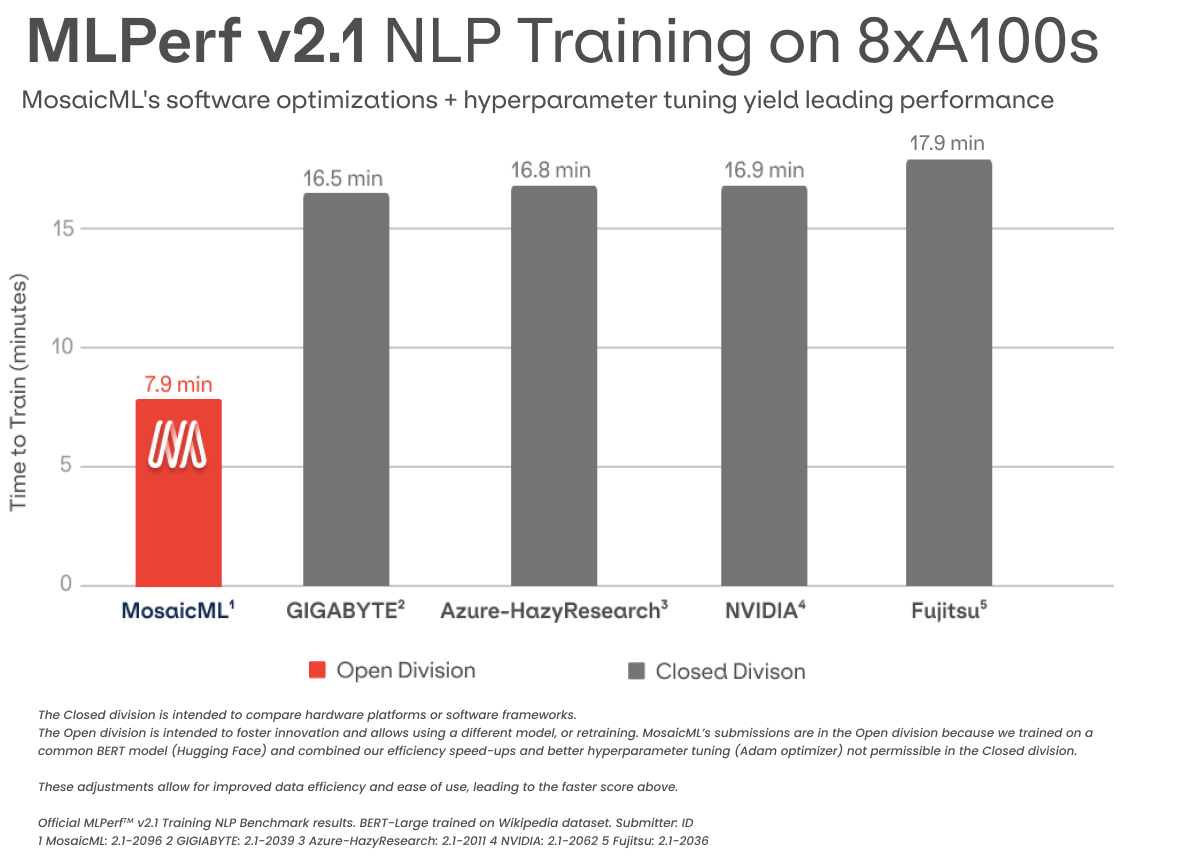
MosaicML leads the MLPerf NLP results, delivering a score of 7.9 minutes on 8x NVIDIA A100 GPUs in the Open Division, thanks to algorithmic and systems optimizations delivered through our platform.
A common perception in machine learning is that it's too hard - and too expensive - to train NLP models from scratch. Instead, most companies are fine-tuning existing models that are pre-trained on generic text data such as all of Wikipedia.
We're on a mission to change that narrative so that anyone can train NLP models from scratch on domain-specific data that's relevant to their industry. Our ultimate goal: lower the cost and time of training, and give companies the ability to unlock new capabilities and better differentiate their products.
That's why we're excited to announce that in today's MLPerf results, MosaicML achieved leading NLP performance. We accelerated the training of a Hugging Face BERT model by 2.7x1 with our software and algorithmic optimizations, which can be automatically enabled in our MosaicML platform.
Results
Our submission uses our open source library Composer, built on top of PyTorch, to easily plug in and test different optimizations. We submitted two configurations to the NLP benchmark in the Open division:
- Baseline: We used the popular BERT-Large model from Hugging Face, and set a strong baseline by applying mixed precision and tuning the hyperparameters. Notably, the Adam optimization converged much faster than the closed division's mandated LAMB optimizer.
- Optimized: To speed up the training, we added several optimizations to the Baseline: Unpadding, Flash Attention, FusedLayerNorm, FusedDropoutAddLayerNorm, and FusedDenseGeLuDense.
Our system and algorithmic optimizations achieve a 2.7x speed-up on training the NLP benchmark compared to a Hugging Face baseline1 (Figure 2). Importantly, both the baseline and the optimized submissions used the same hyperparameters, for a fair comparison.
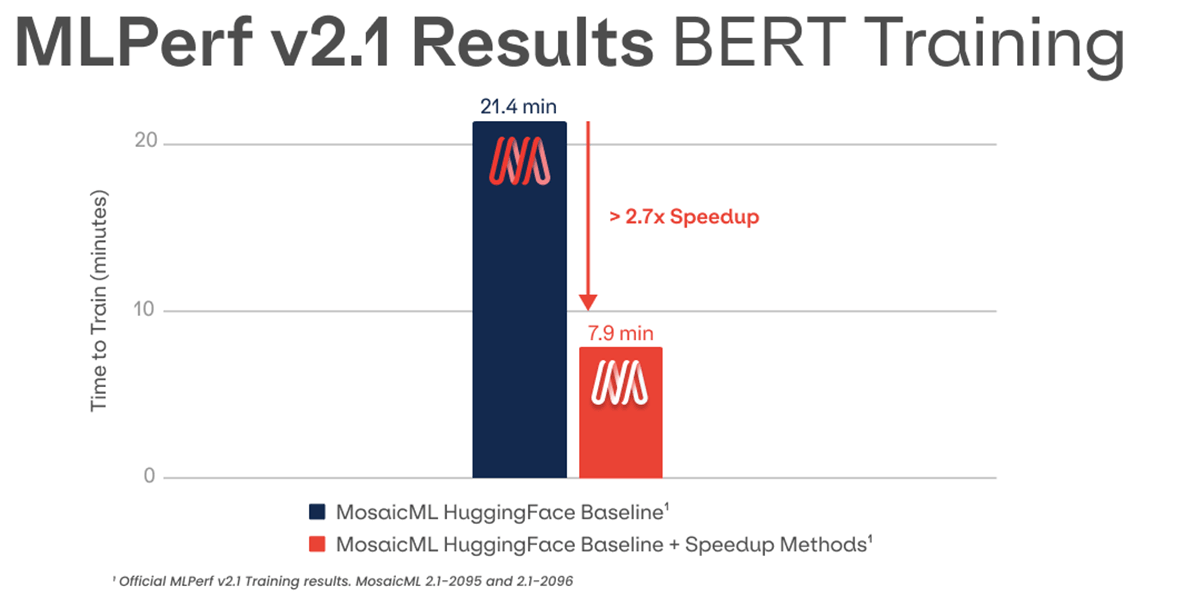
Leading NLP Performance
In comparison, NVIDIA's submission on similar hardware in the Closed division reaches the same accuracy in 16.9 minutes. Our Open division submission is 2.1x faster (Figure 3).
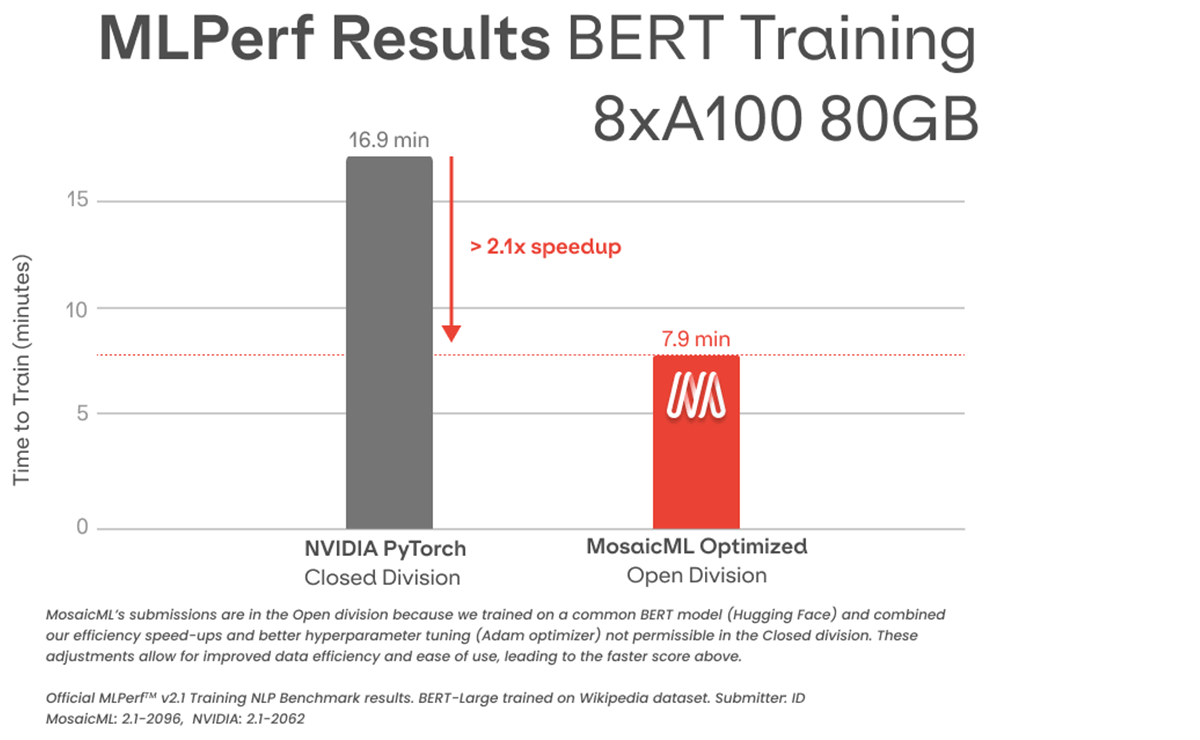
However, there are several important differences between our submissions:
- Ease of use over speed. Our codebase sacrifices some raw speed in favor of code that is easier to use and modify through the implementation of a generic Trainer, instead of a bespoke training loop with custom optimizations. On a samples-per-second basis, our submission is 1.7x slower than NVIDIA's submission.
- Better data efficiency. We found that when using a different optimizer (Decoupled Adam) that is permissible in the open division and widely used with our customers, our training takes 3.5x fewer samples to reach the same accuracy.
To sum up: our submission achieved leading NLP performance with a customizable codebase that is easy to use with your own data.
MLPerf-Level Speed with MosaicML
Knowing when - and how - to use which optimization methods with what models is difficult - and can change based on your hardware and system configurations! To save our customers' valuable time, we built the MosaicML Platform, which was used for our MLPerf submission. The MosaicML platform is an optimized infrastructure and software stack for training deep learning models.
Enabling MLPerf-level speed is easy: you can engage our automatic optimization feature that profiles your code and automatically applies the right speed-up recipes with just a single command-line flag ("-o1")!
mcli run -f bert.yaml -o1Our customers want to focus on modeling, and not spend time dealing with performance optimization. Leave that to our automated software built by our team of efficiency experts and researchers.
Ready to build the best models in the shortest time at the lowest cost? Get started by signing up for a free trial!
1 Official MLPerf v2.1 Training results. MosaicML HuggingFace Baseline: 2.1-2095; MosaicML HuggingFace Baseline + Speedup Methods 2.1-2096
2 The MLPerf NLP score measures time to train of BERT-Large to 0.72 Masked LM Accuracy on Wikipedia dataset.