
With MosaicML, you can now evaluate LLMs and Code Generation Models on code generation tasks (such as HumanEval, with MBPP and APPS coming soon), with an effortless, end-to-end secure code evaluation framework. We handle all the requirements of sandboxing serverless compute, making code evaluation a seamless new feature in the MosaicML platform.
In the rapidly evolving landscape of large language models (LLMs), code generation and completion have emerged as one of the industry’s most important use cases. From GitHub Copilot to Replit’s GhostWriter, an LLM trained on MosaicML’s very own Composer stack, code generation models have been adopted industry-wide. Even general purpose models like ChatGPT are most commonly used for writing code, according to a survey of business leaders by Pollfish.
With increased demand for model-generated code comes an equal need for metrics to evaluate model performance on these tasks. These evaluations come in various forms, such as the open-source HumanEval dataset. A popular approach that tests the generalization of code evaluation is In-Context Learning, as highlighted in our previous blog post, where the model must use provided context to complete the coding task. For reference, here is an example using the Fibonacci sequence:
def fib(n):
"""
Define a function that calculates the n-th Fibonacci number.
>>> fib(10)
55
"""
# add your code hereAt first glance, this seems simple. To evaluate, just query the model and run the code snippets to verify correctness. However, LLM-generated code could contain all kinds of malicious code, from SQL injection to connection to the Internet and much more. (A prime example is the polymorphic malware generated by ChatGPT in an experiment by the security company HYAS InfoSec.) After all, these models are simply trained on large amounts of language (and often code data) without structured schema for generating syntactically and logically sound code. We can’t treat code evaluation like other English language metrics, because we can’t execute them safely without creating a fully isolated secure sandbox environment. (We’ll address how we tackle this critical security issue in further detail shortly).
We’ve added our own secure code evaluation framework to MosaicML Composer that works out of the box with little overhead to the user, even on large distributed training runs. Users can now flexibly integrate secure code evaluation directly into any of their MosaicML-supported workloads, from pretraining massive models to fine-tuning tasks. For example, given a configured Lambda, the below code snippet below will run secure code evaluation without any additional steps:
from composer.metrics import InContextLearningCodeEvalAccuracy
# setup AWS credentials in CODE_EVAL_API_KEY and CODE_EVAL_URL
code_eval_metric = InContextLearningCodeEvalAccuracy()
# this runs LLM-generated code securely
code_eval_metric.update(
batch,
outputs,
labels
)
code_eval_metric.compute()For users of LLM Foundry, a future release will make this even easier to invoke—just provide your dataset path and go.
For this blog post, we will compare our code evaluation framework against industry-standard evaluation harnesses that support a number of code generation test sets. While these evaluation harnesses support a large variety of code generation tasks, they lack the ability to perform secure code evaluation simply, relying on users to manually spin up their own instances and scripts.
In the rest of this post, we’ll lay out the work we have done to deliver secure code evaluation in two sections:
- We describe the architecture of our secure code evaluation framework, which seamlessly integrates code evaluation with the training loop. For the user, adding this functionality is as simple as a one-line change.
- We benchmark our secure code evaluation implementation, and show that it is low cost and as accurate as the industry state of the art.
Seamless Secure Code Evaluation Architecture
Currently, training and evaluating code generation models can take days to months even on large GPU clusters. That’s why it’s important to have code evaluation running continually during training so that we can easily detect any bad training dynamics on the fly. Current evaluation harnesses that support secure code evaluation, like BigCode, require significant manual overhead and configuration. They place the onus on the user, requiring the user to spin up custom Docker images or scripts to configure and copy data to their own secure instances.
Instead, at MosaicML, we designed a seamless and automatic path so secure code eval "just works,” abstracting away the underlying infrastructure (see Figure 1). Instead of relying on the user to create new remote instances for each evaluation—a costly operation due to the requirements of maintaining server instances—we use serverless compute (in our case, AWS Lambda).
Using AWS Lambda instead of the standard EC2 instance with 2 vCPUs can be up to 7x cheaper, especially since it scales faster and can handle high request rates1.
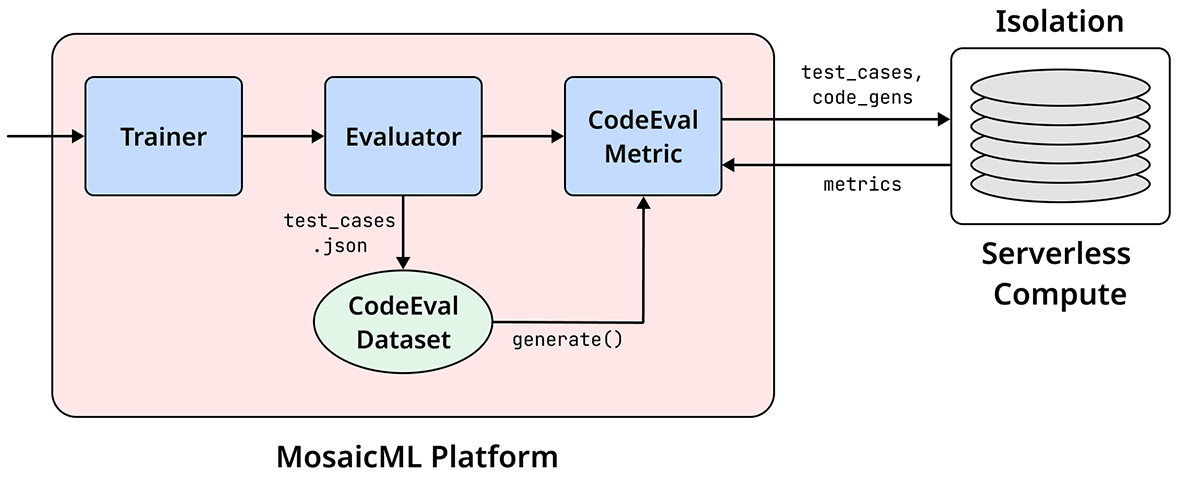
These serverless compute instances ensure both quick startup (under one second as per AWS Documentation) and isolated compute, as each Lambda instance we create is only spun up for the duration of the invocation and is unable to connect to the internet, due to VPC permissioning. Hence, Lambda instances are exactly the secure sandbox we desire, perfect for running code!
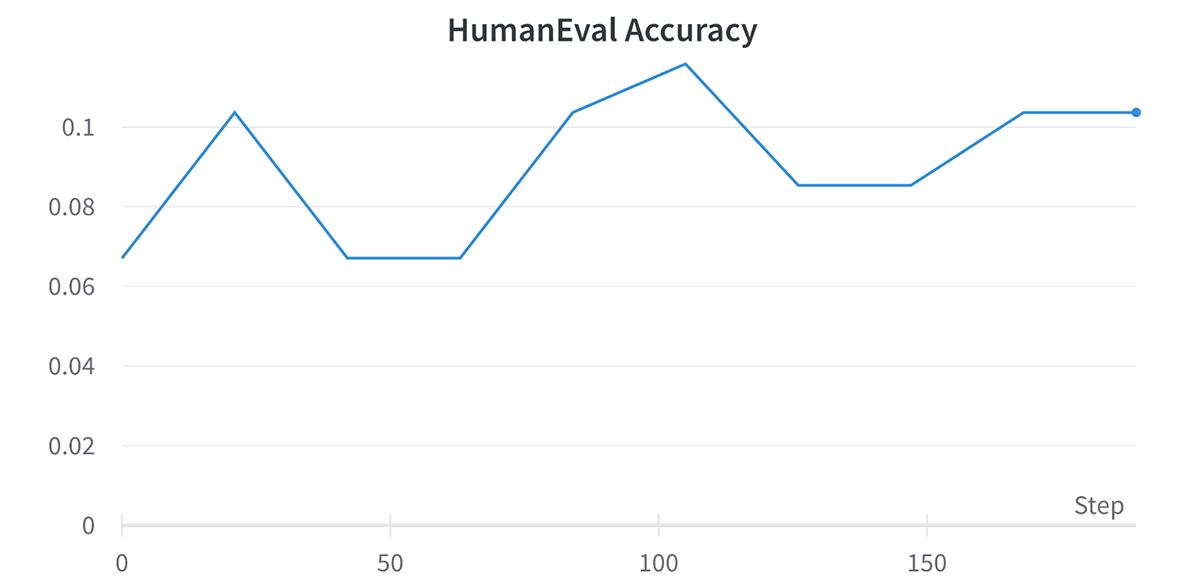
In Composer, we now directly ping the Lambda instances live, enabling us to securely evaluate code generations on the fly. To our knowledge, our codebase is the first to provide this capability! And on the MosaicML platform, with our existing In-Context Learning stack, our forthcoming code evaluation feature will even spin up and set up the Lambdas on behalf of the user, requiring no additional overhead beyond the user’s path to the desired dataset. The magic is all managed for you! For the user, it’s as easy as opening your logger of choice and seeing the graph pop up immediately, just like in Figure 2.
Benchmarking Secure Code Evaluation
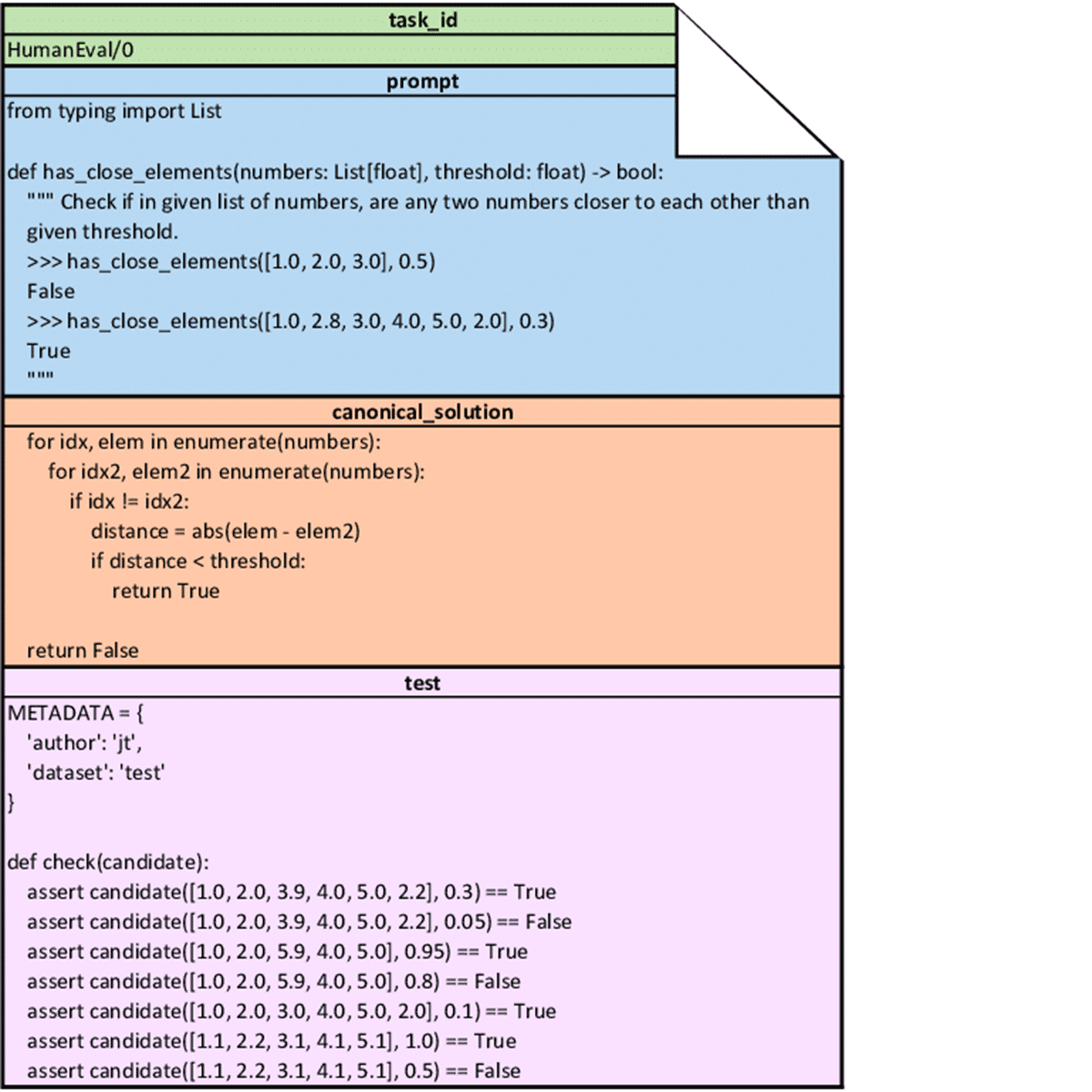
Not only is our secure code evaluation platform seamlessly integrated with our stack, we have benchmarked it on the HumanEval dataset to ensure that our implementation is consistent with the current industry standard. The HumanEval dataset is a series of 164 code function declarations and continuations, published by OpenAI in 2021 and depicted in Figure 2, which we have post-processed into a series of test cases from the original functional solution.
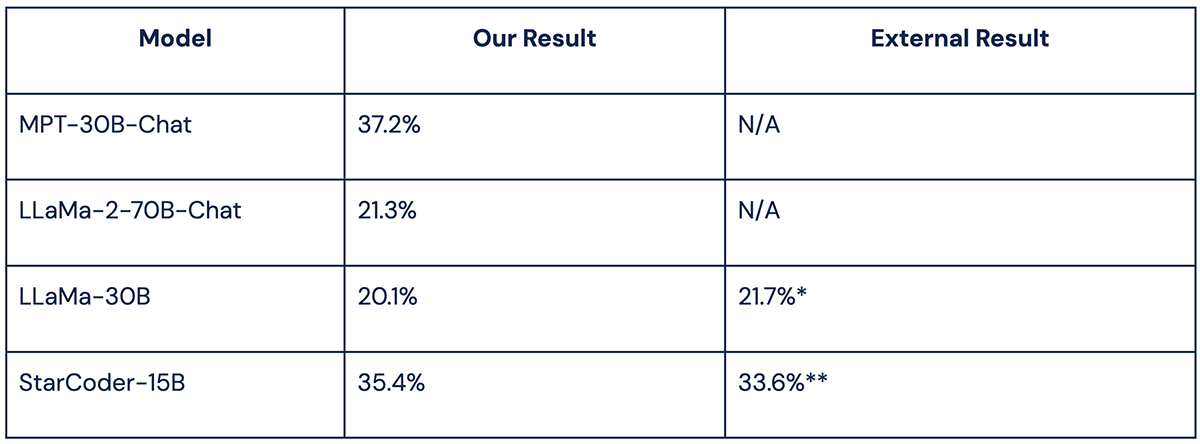
For a series of over 30 models, we evaluated the results that our framework achieved on HumanEval, which are highlighted in both our MPT-30B launch post and our LLM evaluation page, the first of which includes references to externally reported numbers that we verify. A few quick highlights are displayed below in Table 1:
Stay in Touch for Future Developments
Even though we have secure code evaluation released to the world in our latest version of Composer, we’re just getting started. We’ll start rolling out our secure code evaluation product, with support for Lambda setup without any user overhead, in limited preview to our customers on the MosaicML Platform in the next few weeks.
In the coming months, we’ll add support in LLM Foundry for more code datasets and languages, such as Mostly Basic Python Problems (MBPP), APPS, C++, Javascript, and more! To try it out, follow the Composer documentation, coming in our next stable release, with the dataset of your choice.
Keep up to date with the latest on MosaicML products by following us on Twitter, and if you have any feedback, please reach out on our Community Slack. If you’re a prospective customer and would like to chat with the MosaicML team, fill out our Get Started form.